Markitdown
综合介绍
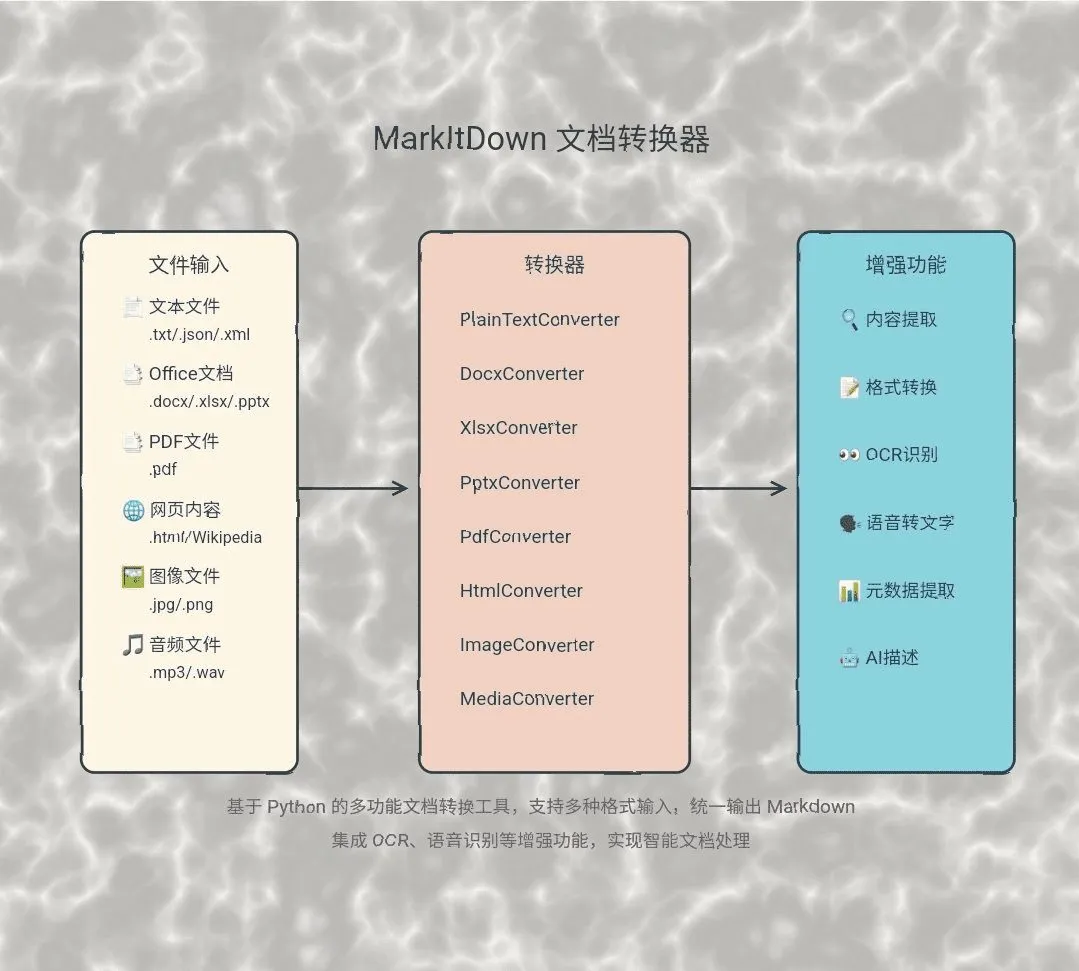
Markitdown是一个由微软开发的轻量级Python工具,主要功能是将多种不同格式的文件转换成Markdown。这个工具在处理需要输入给大语言模型(LLM)的文本时特别有用,因为它能够保留文档原有的重要结构,比如标题、列表、表格和链接等,同时又保持了Markdown格式的简洁性。支持转换的文件类型非常广泛,包括PDF、Office三件套(Word, PowerPoint, Excel)、图片(可提取EXIF元数据和进行OCR文字识别)、音频(可提取元数据和进行语音转录)、HTML、常见的文本格式(如CSV, JSON, XML),甚至还可以处理ZIP压缩包和YouTube链接。虽然转换后的Markdown内容可读性不错,但它的主要设计目标是为文本分析工具提供格式化的输入,而非追求与源文件一模一样的高保真视觉效果。
功能列表
- 多种文件格式支持: 能够转换PDF、PowerPoint、Word、Excel等常见办公文档。
- 多媒体文件处理: 支持从图片中提取EXIF元数据并通过OCR识别文字,以及从音频文件中提取元数据和进行语音转录。
- 结构化数据转换: 可以处理HTML、CSV、JSON、XML等结构化和半结构化数据文件。
- 压缩包与网络内容: 支持遍历ZIP压缩包内的文件进行转换,也能处理YouTube链接和EPub电子书。
- 保留文档结构: 在转换过程中,会尽力保留原始文件中的标题、列表、表格、链接等关键结构。
- 命令行工具: 提供了简单的命令行界面,用户可以通过终端快速转换文件。
- Python API: 开发者可以通过其提供的Python API,将文件转换功能集成到自己的应用程序中。
- 插件化架构: 支持第三方插件,用户可以根据需要启用或开发新插件来扩展功能。
- 集成Azure文档智能: 可以利用Azure的文档智能服务来提升PDF等文件的转换质量。
- 大语言模型集成: 支持接入大语言模型(如GPT-4o)对图片进行描述。
使用帮助
Markitdown作为一个Python库,主要通过命令行或Python代码来使用。它的设计目标是尽可能简化文件到Markdown的转换过程。
安装流程
在使用Markitdown之前,需要确保你的系统已经安装了Python 3.10或更高版本。官方建议在一个虚拟环境中安装和使用Markitdown,以避免不同项目之间的依赖冲突。
- 创建并激活虚拟环境你可以使用Python自带的
venv模块来创建虚拟环境:python -m venv .venv source .venv/bin/activate # 在Windows上使用.venv\Scripts\activate - 安装MarkitdownMarkitdown的依赖项被分成了不同的功能组,你可以根据需要来安装。如果想体验全功能,可以直接安装
[all]版本,这也是向后兼容旧版本的推荐方式。pip install 'markitdown[all]'如果你只需要处理特定的文件类型,比如PDF和Word文档,可以选择性地安装依赖:
pip install 'markitdown[pdf, docx]'目前支持的可选依赖组包括:
[pptx]、[docx]、[xlsx]、[xls]、[pdf]、[outlook]、[az-doc-intel]、[audio-transcription]和[youtube-transcription]。
如何操作
安装完成后,你有两种主要的方式来使用Markitdown。
1. 命令行使用
命令行是最直接的使用方式,适合快速的文件转换任务。
- 基本转换:将一个文件转换后直接在终端输出Markdown内容。
markitdown path-to-file.pdf - 输出到文件:使用
-o参数可以将转换结果保存到一个新的Markdown文件中。markitdown path-to-file.pdf -o document.md - 通过管道操作:Markitdown也支持Linux/macOS下的管道操作,可以方便地与其他命令组合使用。
cat path-to-file.pdf | markitdown > document.md - 使用插件:默认情况下,插件是禁用的。你可以先列出当前环境已安装的插件。
markitdown --list-plugins然后在转换时通过
--use-plugins参数来启用它们。markitdown --use-plugins path-to-file.pdf
2. Python API使用
对于需要将文件转换功能集成到软件项目中的开发者,使用Python API是更好的选择。
- 基础用法:导入
MarkItDown类,创建一个实例,然后调用convert方法即可。from markitdown import MarkItDown # 初始化,默认禁用插件 md = MarkItDown(enable_plugins=False) # 转换指定路径的文件 result = md.convert("test.xlsx") # 打印转换后的文本内容 print(result.text_content) - 使用Azure文档智能:如果你拥有Azure的文档智能服务终结点,可以在初始化时传入,以获得更高质量的PDF识别效果。
from markitdown import MarkItDown md = MarkItDown(docintel_endpoint="<your_document_intelligence_endpoint>") result = md.convert("test.pdf") print(result.text_content) - 集成大语言模型进行图片描述:Markitdown还可以利用大语言模型(如OpenAI的GPT-4o)来为图片生成描述性文字。你需要提供一个LLM客户端实例和模型名称。
from markitdown import MarkItDown from openai import OpenAI # 创建一个OpenAI客户端 client = OpenAI() # 初始化MarkItDown,并传入LLM客户端和模型 md = MarkItDown(llm_client=client, llm_model="gpt-4o") # 转换图片 result = md.convert("example.jpg") print(result.text_content)
Docker容器中使用
如果你熟悉Docker,也可以在容器环境中使用Markitdown,这样可以避免在本地安装Python和各种依赖。
- 构建Docker镜像:在项目的根目录运行以下命令。
docker build -t markitdown:latest . - 运行容器进行转换:通过管道将本地文件内容输入到容器中运行的Markitdown,并将结果重定向到输出文件。
docker run --rm -i markitdown:latest < ~/your-file.pdf > output.md
应用场景
- 数据预处理与分析在自然语言处理(NLP)或数据分析项目中,经常需要处理大量非结构化的文档,如PDF报告、Word文档和网页。Markitdown可以将这些来源不同、格式各异的文件统一转换为干净的Markdown文本,极大地简化了数据清洗和预处理的流程,使研究人员和分析师能更专注于后续的文本分析和模型训练。
- 构建检索增强生成(RAG)系统RAG系统通过从知识库中检索相关信息来提升大语言模型的回答质量。Markdown因其结构清晰、接近自然语言的特点,是构建知识库的理想格式。Markitdown可以将企业内部的各种文档(如产品手册、技术文档、FAQ)批量转换为Markdown格式,作为RAG系统的知识来源,从而让模型能够提供更准确、更具上下文的回答。
- 个人知识管理许多知识管理软件(如Obsidian, Joplin)都使用Markdown作为核心格式。用户可以使用Markitdown将网络文章、电子书、工作文档等外部资料快速转换为Markdown格式,方便地导入到自己的知识库中进行统一管理、搜索和链接。
- 自动化内容提取Markitdown可以集成到自动化工作流中,例如使用n8n或Zapier。当有新的邮件附件、网页内容或云存储中的文件时,可以自动触发Markitdown进行转换,提取其中的文本内容,并将其归档或发送到其他应用中,实现无人值守的内容处理流程。
QA
- Markitdown支持哪些文件类型?Markitdown支持非常广泛的文件类型,包括:
- 办公文档:Word (
.docx), PowerPoint (.pptx), Excel (.xlsx,.xls) - 文本文档:PDF, HTML, CSV, JSON, XML
- 多媒体:图片 (JPG, PNG等,可提取EXIF和OCR文本), 音频 (WAV, MP3,可进行语音转录)
- 其他:ZIP压缩包, EPub电子书, YouTube链接。
- 办公文档:Word (
- 转换后的Markdown和源文件看起来完全一样吗?不完全一样。Markitdown的核心目标是保留文档的“结构”和“内容”,而非精确复制其“样式”。它会尽力将标题、列表、表格等元素转换为对应的Markdown语法,但字体、颜色、布局等视觉样式信息会丢失。因此,输出结果主要是为了机器可读和文本分析,而不是为了完美的视觉呈现。
- 使用Markitdown是否需要付费?不需要。Markitdown是一个在MIT许可下发布的开源项目,你可以免费使用它,甚至可以修改和重新分发。
- 我需要安装很多依赖吗?不一定。Markitdown采用了可选依赖的安装方式。你可以只安装处理特定文件类型(如
[pdf]或[docx])所需的最小依赖集,也可以通过[all]选项一次性安装所有依赖以获得完整功能。 - Markitdown可以离线使用吗?是的。Markitdown作为一个Python库,一旦安装完成,其核心的文件转换功能完全可以在本地离线运行。但某些高级功能,如使用Azure文档智能进行高质量PDF转换或调用大语言模型进行图片描述,则需要网络连接。